Scheduled DAG with pandas and sklearn from scratch.¶
Audience: Users coming from MLOps to Lightning Apps, looking for more flexibility.
Level: Intermediate.
In this example, you will learn how to create a simple DAG which:
Download and process some data
Train several models and report their associated metrics
and learn how to schedule this entire process.
Find the complete example here.
Step 1: Implement your DAG¶
Here is an illustration of the DAG to implement:
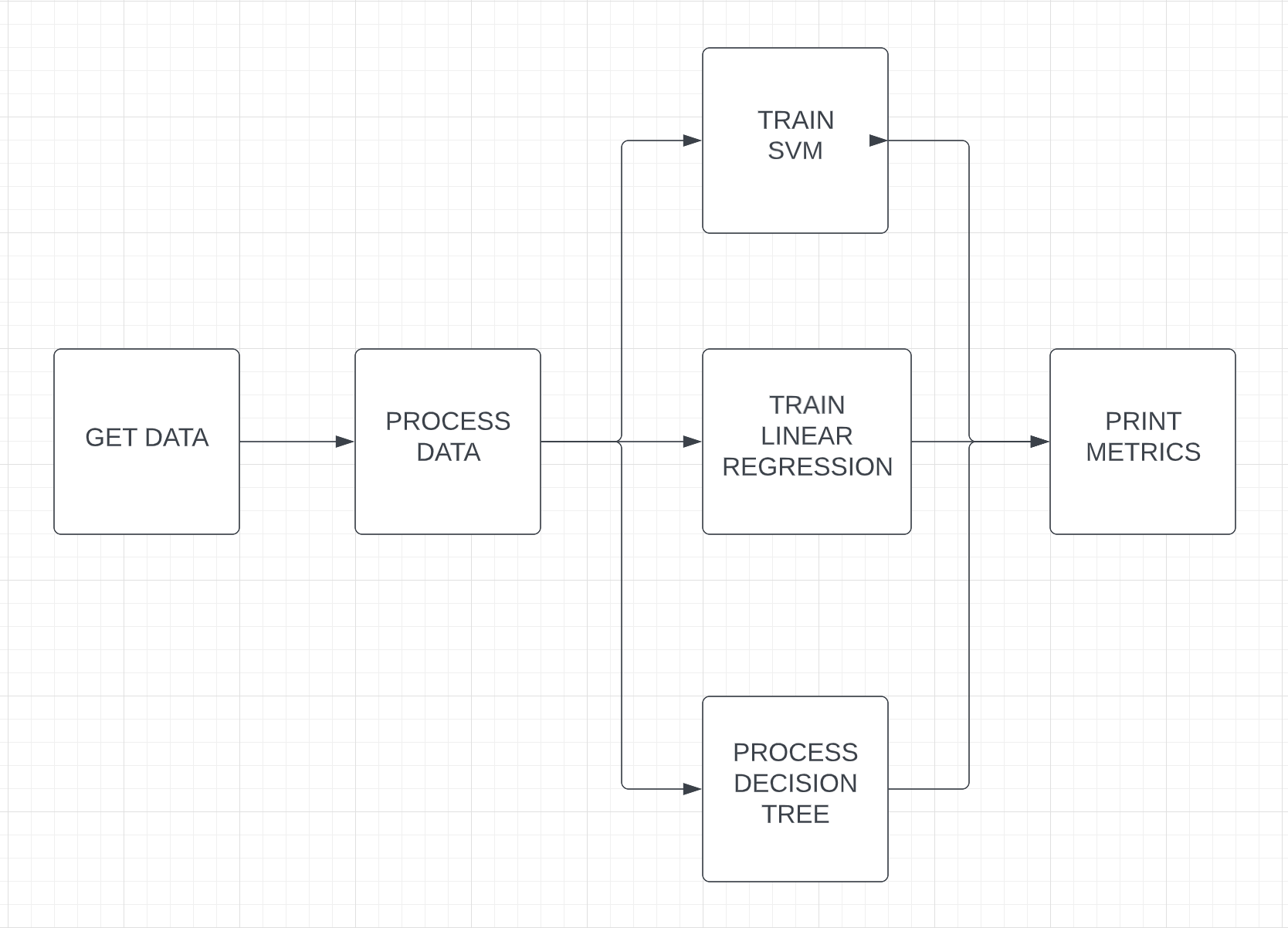
First, let’s define the component we need:
DataCollector is responsible to download the data
Processing is responsible to execute a
processing.pyscript.A collection of model work to train all models in parallel.
class DAG(LightningFlow):
"""This component is a DAG."""
def __init__(self, models_paths: list):
super().__init__()
# Step 1: Create a work to get the data.
self.data_collector = GetDataWork()
# Step 2: Create a tracer component. This is used to execute python script
# and collect any outputs from its globals as Payloads.
self.processing = TracerPythonScript(
get_path("processing.py"),
outputs=["X_train", "X_test", "y_train", "y_test"],
)
# Step 3: Create the work to train the models_paths in parallel.
self.dict = Dict(**{
model_path.split(".")[-1]: ModelWork(model_path, parallel=True) for model_path in models_paths
})
# Step 4: Some element to track components progress.
self.has_completed = False
self.metrics = {}
And its run method executes the steps described above.
def run(self):
# Step 1 and 2: Download and process the data.
self.data_collector.run()
self.processing.run(
df_data=self.data_collector.df_data,
df_target=self.data_collector.df_target,
)
# Step 3: Launch n models training in parallel.
for model, work in self.dict.items():
work.run(
X_train=self.processing.X_train,
X_test=self.processing.X_test,
y_train=self.processing.y_train,
y_test=self.processing.y_test,
)
if work.test_rmse: # Use the state to control when to collect and stop.
self.metrics[model] = work.test_rmse
work.stop() # Stop the model work to reduce cost
# Step 4: Print the score of each model when they are all finished.
if len(self.metrics) == len(self.dict):
print(self.metrics)
self.has_completed = True
Step 2: Define the scheduling¶
class ScheduledDAG(LightningFlow):
def __init__(self, dag_cls, **dag_kwargs):
super().__init__()
self.dags = List()
self._dag_cls = dag_cls
self.dag_kwargs = dag_kwargs
def run(self):
"""Example of scheduling an infinite number of DAG runs continuously."""
# Step 1: Every minute, create and launch a new DAG.
if self.schedule("* * * * *"):
print("Launching a new DAG")
self.dags.append(self._dag_cls(**self.dag_kwargs))
for dag in self.dags:
if not dag.has_completed:
dag.run()
app = LightningApp(
ScheduledDAG(
DAG,
models_paths=[
"svm.SVR",
"linear_model.LinearRegression",
"tree.DecisionTreeRegressor",
],
),
)
